We ran an entire AI pipeline through one model for three months.
Then we looked at the invoice.
Intent classification. Entity extraction. Summarization. Complex multi-step reasoning. All routed to the same endpoint. Same model. Same cost per call.
We were paying Formula 1 prices for Grocery runs.
The fix wasn’t finding a better model. It was building tiered inference – a routing layer that decides which model gets called based on task complexity.
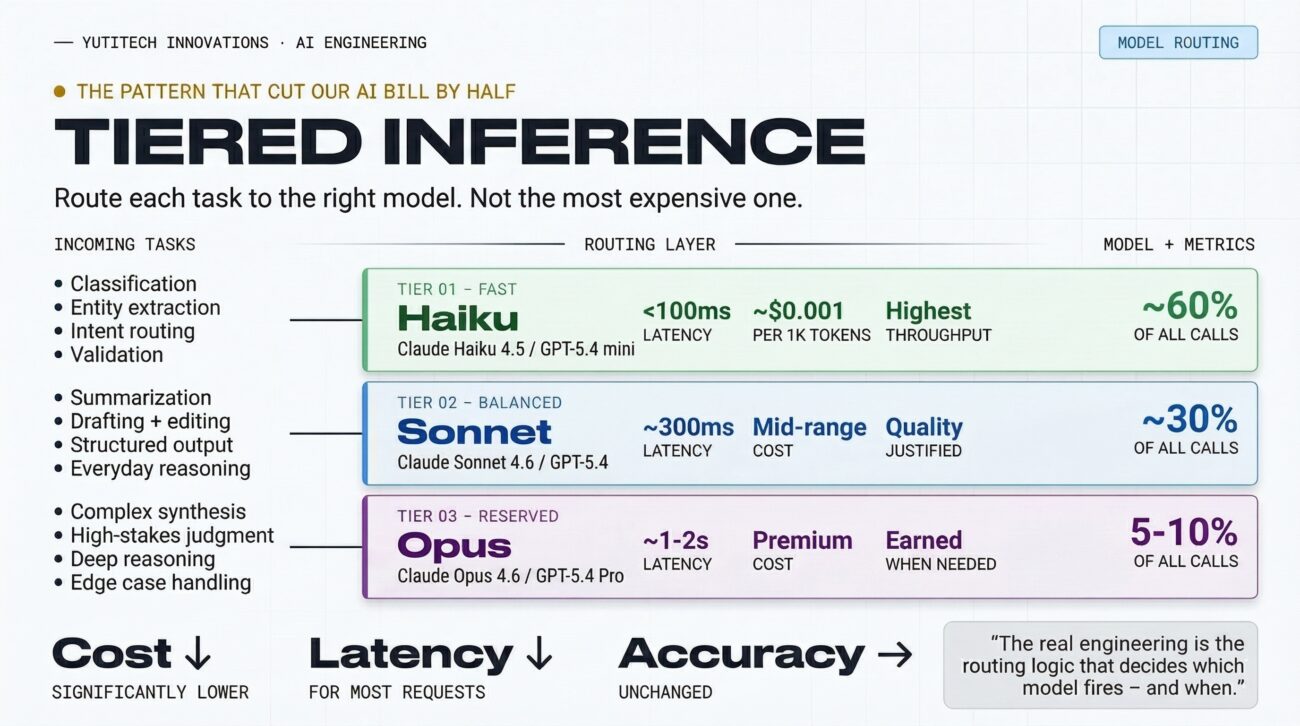
Here’s what our three-tier stack looks like in production:
Tier 1 · Fast (Claude Haiku 4.5 / GPT-5.4 mini)
Classification, routing, extraction, validation. Sub-100ms. ~60% of volume. Costs almost nothing.
Tier 2 · Balanced (Claude Sonnet 4.6 / GPT-5.4)
Summarization, drafting, structured output, reasoning. Quality justified by task.
Tier 3 · Reserved (Claude Opus 4.6 / GPT-5.4 Pro)
Complex synthesis, edge cases, high-stakes judgment. Runs maybe 5–10% of calls.
The real engineering isn’t choosing between models. It’s building the routing logic that decides which one fires – and when to escalate.
After the rebuild: latency down, costs down significantly, accuracy unchanged.
The question was never “which model is best?”
It’s “which model is right for this task, at this latency budget, at this cost ceiling?”
That’s the difference between AI engineering and AI experimentation.
—
At Yutitech, this is how we build AI backends – not just wiring up APIs, but designing systems that treat model selection as an architectural decision.
What does your model routing look like? Running everything through one endpoint, or have you tiered it? Drop your stack below. ↓
____________________________________________________________________________________________________________
Written by Sarthak Kumar
AI Engineer, Yutitech Innovations Pvt Ltd